

Azure VM : Custom Data vs. User Data
If you’ve ever provisioned a Virtual Machine (VM) in Azure, you’ve likely stared at the "Advanced" tab during creation and wondered, "Should I put my script in Custom Data? Or is User Data the way to go?"
While both features allow you to inject data into your VM, they serve very different phases of the VM's lifecycle. Confusing them can lead to automation failures or security gaps.
In this post, we’ll break down what can be used in each, the critical differences, and—most importantly—how to secure them.

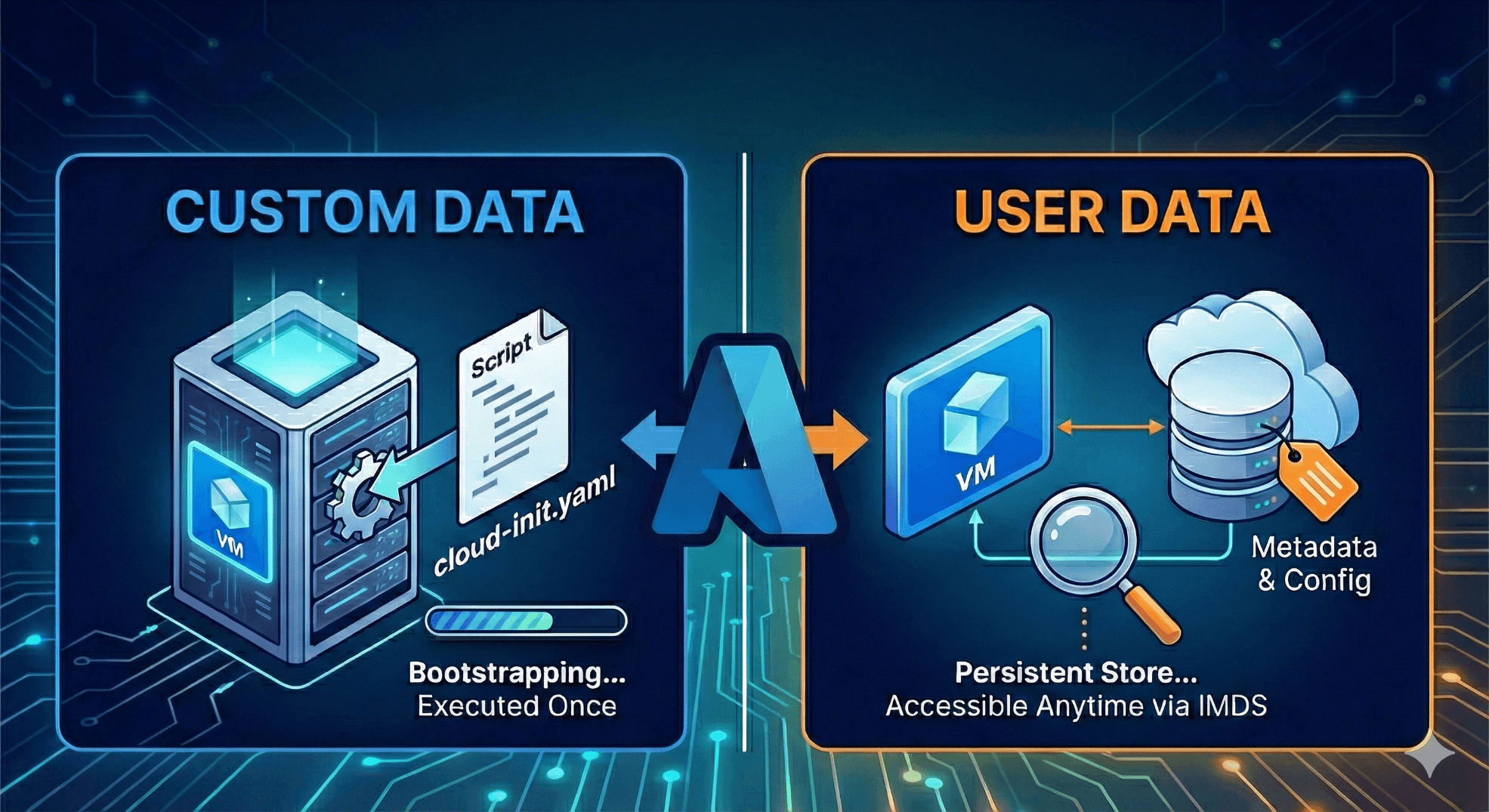
1. Custom Data: The "Bootstrapper"
Custom Data is the classic, tried-and-true method for bootstrapping Azure VMs. Think of it as the "instruction manual" you hand to the VM the very first time it wakes up.
What is it used for?
It is primarily designed for provisioning. It tells the VM how to configure itself immediately after creation.
What can be used in it?
Cloud-init files (Linux): This is the most common use case. You pass a YAML file that creates users, installs packages (like Nginx or Docker), and writes configuration files.
Shell Scripts (Bash): Simple startup scripts for Linux.
PowerShell Scripts (Windows): While you can put them here, Windows does not execute them automatically by default.
Configuration Files: Any base64-encoded file (config, JSON, XML).
How it works
Linux: If your image uses
cloud-init(standard on Ubuntu, RHEL, CentOS, etc.), it automatically detects, decodes, and executes the Custom Data during the first boot only.Windows: Azure places the data in a binary file at
%SYSTEMDRIVE%\AzureData\CustomData.bin. It sits there passively. To run it, you must use a separate tool (like the Custom Script Extension) or have a scheduled task pre-baked into your image to look for and execute this file.
2. User Data: The "Persistent Store"
User Data is a newer feature designed to offer a persistent data store that stays with the VM throughout its life.
What is it used for?
It is designed for runtime configuration and metadata that your application might need to check periodically. Unlike custom data, it is meant to be accessible easily via standard APIs from within the VM.
What can be used in it?
Environment Flags: e.g.,
ENV=Production,ClusterID=12345.Version Pins: e.g.,
AppVersion=2.1.0.Bootstrapping Scripts: Modern versions of
cloud-init(21.2+) can consume User Data for provisioning if Custom Data is empty.Custom Config Blobs: A JSON blob containing connection strings (non-sensitive ones!) or feature toggles.
How it works
Persistence: User Data persists for the lifetime of the VM. You can even update it while the VM is running (though the VM won't know unless it polls for changes).
Accessibility: It is available via the Azure Instance Metadata Service (IMDS). Any process inside the VM can retrieve it by querying a local endpoint.
IMDS is a REST API that's available at a well-known, non-routable IP address (169.254.169.254). You can only access it from within the VM. Communication between the VM and IMDS never leaves the host.## For Windows ## Invoke-RestMethod -Headers @{"Metadata"="true"} -Method GET -NoProxy -Uri "http://169.254.169.254/metadata/instance?api-version=2025-04-07" | ConvertTo-Json -Depth 64## For Linux ## curl -s -H Metadata:true --noproxy "*" "http://169.254.169.254/metadata/instance?api-version=2025-04-07" | jq
3. The Comparison Table
| Feature | Custom Data | User Data |
| Primary Goal | Initial Boot/Provisioning | Persistent Configuration/Metadata |
| Execution | Automatic (Linux/cloud-init) | Passive (Data store)* |
| Persistence | Available at boot; hard to retrieve later | Available anytime via API (IMDS) |
| Updateable? | No (Static after creation) | Yes (Can be updated anytime) |
| Retrieval Method | File on disk (ovf-env.xml / .bin) | HTTP Request (IMDS) |
| Size Limit | 64 KB | 64 KB |
\Note: While User Data is passive by default, modern cloud-init can be configured to execute it.*
4. Security
Security is the most critical differentiator. Because both methods involve passing data to a VM, it is tempting to dump secrets (passwords, API keys) here. Do not do this.
Why is it unsafe?
1. Custom Data Risks (The File System Risk)
Exposure: Custom Data is stored as a file on the VM's disk.
Linux: It often resides in
/var/lib/waagent/ovf-env.xmlor/var/lib/cloud/instance/. Any user with read access to these directories (typically root/sudo) can read it.Windows: It sits in
%SYSTEMDRIVE%\AzureData\CustomData.bin.
Logging: If your script prints secrets to the console (stdout/stderr) during execution, those secrets might end up in system logs (
/var/log/cloud-init-output.logor Azure Boot Diagnostics logs), which are viewable from the Azure Portal.
2. User Data Risks (The IMDS Risk)
Open Access: User Data is served via the Instance Metadata Service (IMDS), a local HTTP server at
169.254.169.254.No Authentication: By default, any process running on that VM (not just root/admin) can query this URL and retrieve the data. If an attacker manages to run a simple script on your VM (or exploits a web app vulnerability like SSRF), they can easily read your User Data.
Clear Text: The API returns the data in base64, which is trivially easy to decode. It is effectively clear text.
Best Practices for Security
If you can't put secrets in Custom/User Data, how do you get them into the VM?
Instead of passing the password in Custom Data, pass the instruction to get the password.
Enable a System Assigned Managed Identity on the VM.
Grant that identity access to an Azure Key Vault.
Use Custom Data to run a script (using Azure CLI or PowerShell) that logs in using the Managed Identity (
az login --identity) and fetches the secret from the Key Vault.
Restrict IMDS Access (Defense in Depth): If you use User Data, ensure you are not running untrusted code on the VM. You can also use local OS firewalls (iptables/Windows Firewall) to restrict which users or processes can talk to
169.254.169.254.Assume Visibility: Always assume that anyone with access to the VM (even low-level access) can read everything in Custom Data and User Data. Treat these fields as "public" relative to the VM's internal environment.




